Generating NES-style Music with Machine Learning
Objective
For this project, I wanted to generate NES-style music using some form of machine learning - be it with an existing model or by creating one myself.
Planning
Neural Network Architectures for Music
Music mainfests certain properties that exist ubiquitously across pieces and genres. These features include structure (such as ABA), coherence, self-referencing, and the development of previous phases to elicit a specific response from the listener.
These properties relate to the persistence of some event throughout a single piece - the existence of an event informs later events. A neural network that generates new music well needs to information from events to persist and develop.
While not strictly necessary to produce an output for this project, I wanted to take the opportunity to understand the types of architecture that would be best suited to music generation.
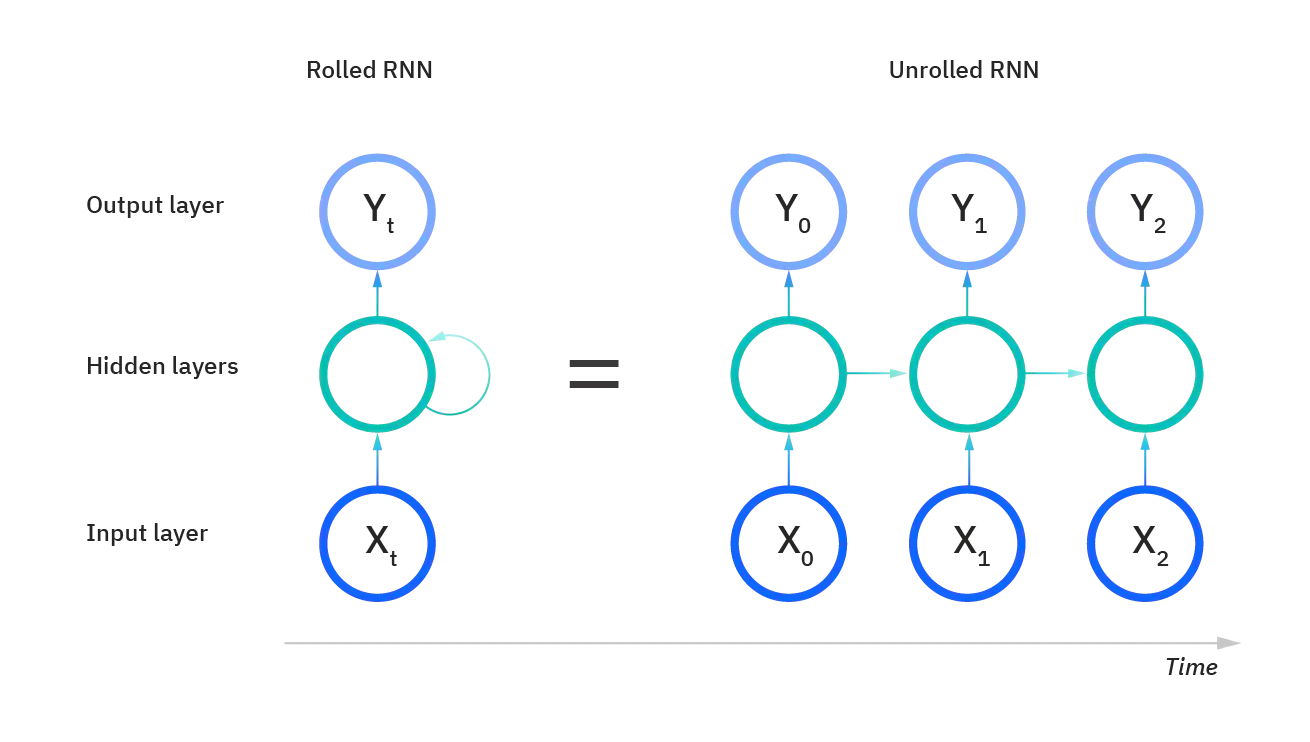
Recurrent Neural Networks (RNNs)
An RNN is the most basic architecture for allowing information to persist. The output of each layer is input into the next, allowing for information from previous inputs to influence the output.
Long Short-Term Memory Networks (LSTMs)
LSTMs were created to solve the problem that previous states have decreasing influence as they get further from a present prediction.
For example, consider trying to predict the last words in the sentence “Alice is allergic to nuts…….She can’t eat peanut butter.” The further back the previous sentence, the harder it is for a neural network to understand the context.
An LSTM has “cells” containing an input, output and forget gate to control the flow of information that is important to creating a prediction.
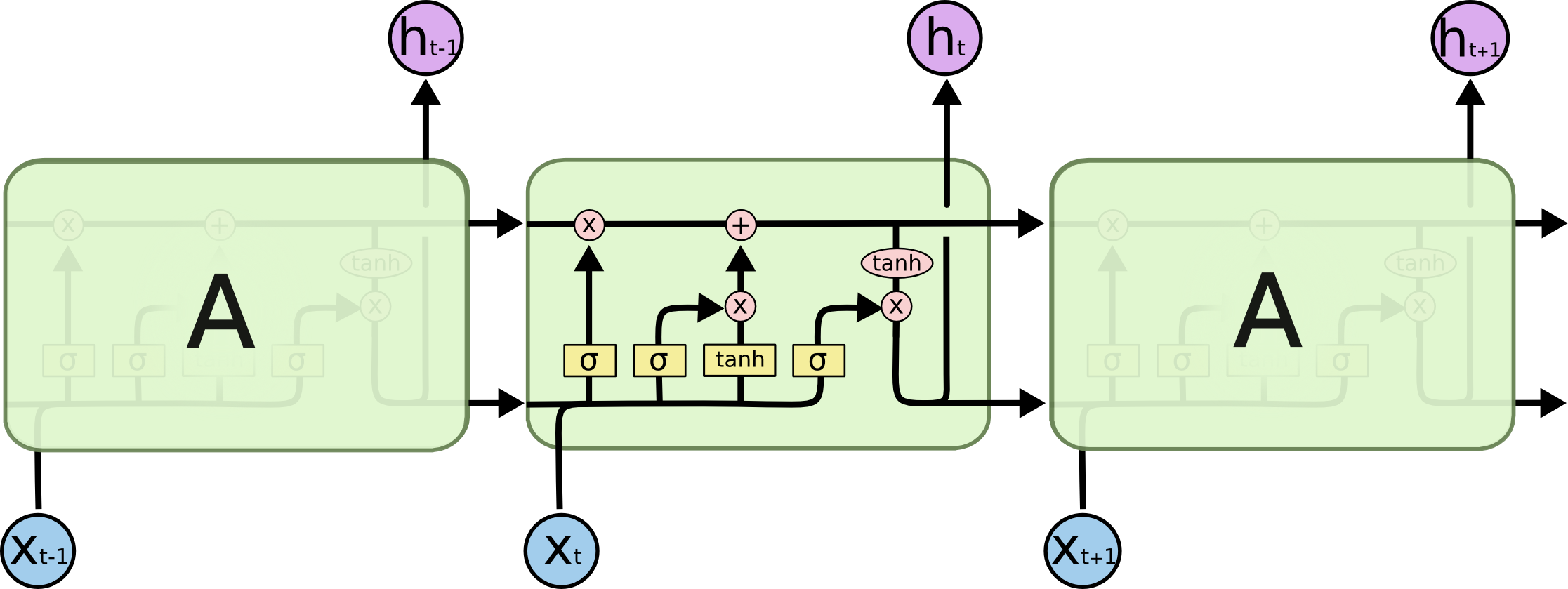
An explanation of LSTM cells is beyond the scope of ths blog post, but those interested can read more here.
Transformers
Transformers use the concept of “self-attention” to persist event information across longer gaps. In self-attention, each event (i.e. a word in a sentence) is given a Query vector, a Key vector and a Value vector. In the word example, the amount of attention to be paid to a particular word from the perspective of another word in the sentence is calculated by taking the dot product of the query vector for the particular word with the key vector for other words in the input sentence. This is called the self-attention score.

After scores are divided by 8 to obtain more stable gradients, self-attention scores are then passed through a Softmax operation so all scores a positive and add up to 1. This gives the probability that one word should pay attention to another.
There is a paper on building a Music Transformer, with example usage.
Variational Autoencoders (VAE)
Another type of neural net architecture of note is the Variational Autoencoder, which is typically used to compose deep generative models. While they lack the ability to persist information from events, they are far more apt at extracting detailed features from data and generating an output that corresponds to that level of detail.
One way of predicting and generating an output given a mass of input data is to encode the features of the input through dimensionality reduction, decode to some output, measure the loss in the decoded output relative to the input data and adjust the encoder/decoder combination accordingly. This is known as an “autoencoder” architecture.
The issue in this approach is that the encoding sits in a latent space, and decoding a random point from that latent space is unlikely to output anything similar to the input.
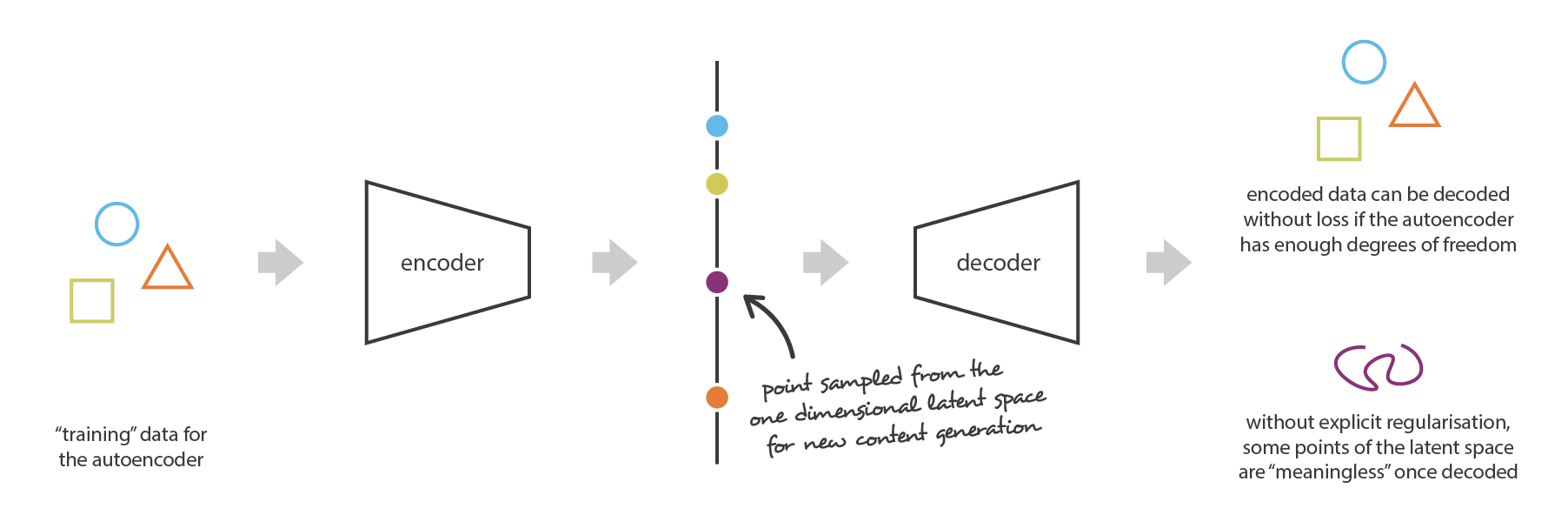
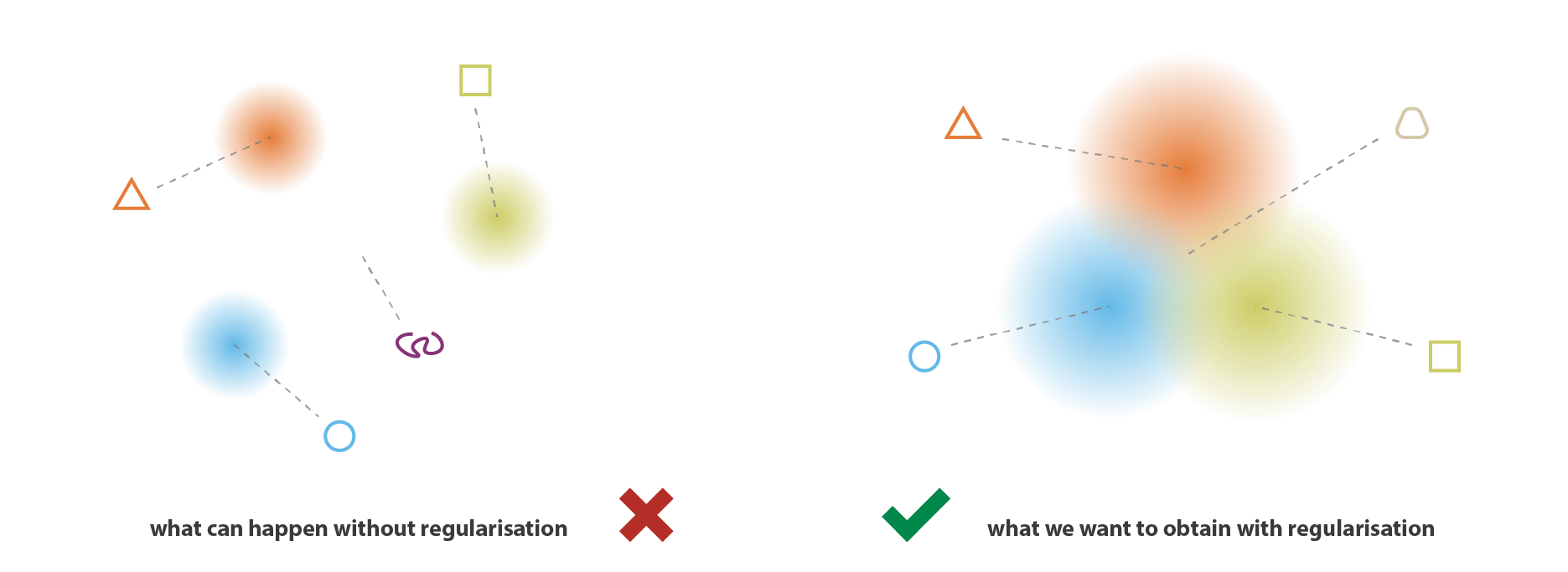
In a VAE, the latent space is regularized during the training process to have two properties:
- Continuity: Two points that are close in the latent space should be similar in their output upon decoding.
- Completeness: Any point in the latent space should give a meaningful output upon decoding.
In order to acheive this, the inputs are encoded not as single points, but as probability distributions in the latent space. This allows for a meaningful output when decoding from any point.
While Variational Autoencoder architectures do not inherently allow information to persist, researchers at Google were able to combine a VAE with a Recurrent Neural Network to create a MusicVAE. This model is useful for creating short but more detailed melodies, between 2-16 bars.
Datasets
- VGMusic
- I ended up scraping all MIDIs from the NES page as my main dataset.
- NES Music Database (w/ Python library)
Implementation
The first step of this project was to map out different ways of generating new music with machine learning. The following is an overview of some of the projects I discovered:
Recurrent Neural Networks for Video Game Music Generation
In this paper, MIDI files are vectorized using the pretty_midi Python library and then input into a simple RNN with a single LSTM layer as per the image below.
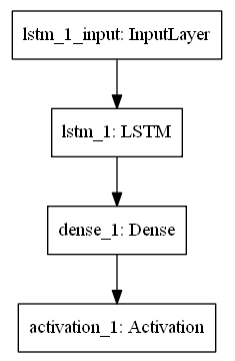
Convolutional Autoencoder
MIDI files were converted into images, described as “bitmap-like matrices”, in order to make the most of machine learning techniques from image-processing. These images were then fed into a convolutional autoencoder.

Creating a Pop Music Generator with the Transformer
Starts by using the Python music21 library to convert piano sheet music into tokens, which is then input to a transformer language model from the fastAI library. You can play around wth the pre-trained model here.
Google Magenta
Google Magenta already has pre-trained models that can be further trained on your own dataset to generate new music. To get my desired output, this seemed like the path of least resistance - I wouldn’t want the project to turn into a shed.
An overview of Magenta models can be found here.
After pip installing magenta alone did not allow me to use my GPU in Tensorflow, I created a new conda virtual environment, first conda installed tensorflow-gpu=2.3.0, then pip installed magenta, and then downgraded the numba library co-installed with magenta to version 0.48.0.
Output
I tried out a few of the different models available in Magenta. Deeper neural nets with larger layer sizes resulted in better outputs, but I found myself memory-constrained training on a gaming laptop with just 6GB of VRAM. I generated ~20 tracks for each model and selected a few that were interesting.
Basic RNN: Produced the most basic tracks. Trained on default settings.
Lookback RNN: This model was designed to help guide the training process towards understanding music structure in the following ways:
- Events from 1-2 bars prior are also input to the model so patterns can be more readily recognised.
- Whether the last event was repeating the event from 1-2 bars prior is also recorded and input, so the model can more easily recognise whether a track is in a repetitive or non-repetitive state.
This was the only model I trained on the NES Music Database dataset, and the output below came from a model trained at layer_size=[256,256], batch_size=16.
Polyphony RNN: This model is capable of generating melodies with simultaneous notes. The output below came from a model trained at layer_size=[256,256], batch_size=16.
I also liked this one even though it isn’t necessarily polyphonic.
Music VAE (2-bar): There are versions of the Music VAE that produce more than 2 bars, but even a shallow network ([64,64]) with batch_size = 1 required more VRAM than my laptop could offer. Thus the result was quite underwhelming, but tracks generated showed more variation than other models.